May 2026 RM-2026-05-LP
Local Providers: Which Open Model Should You Actually Run?
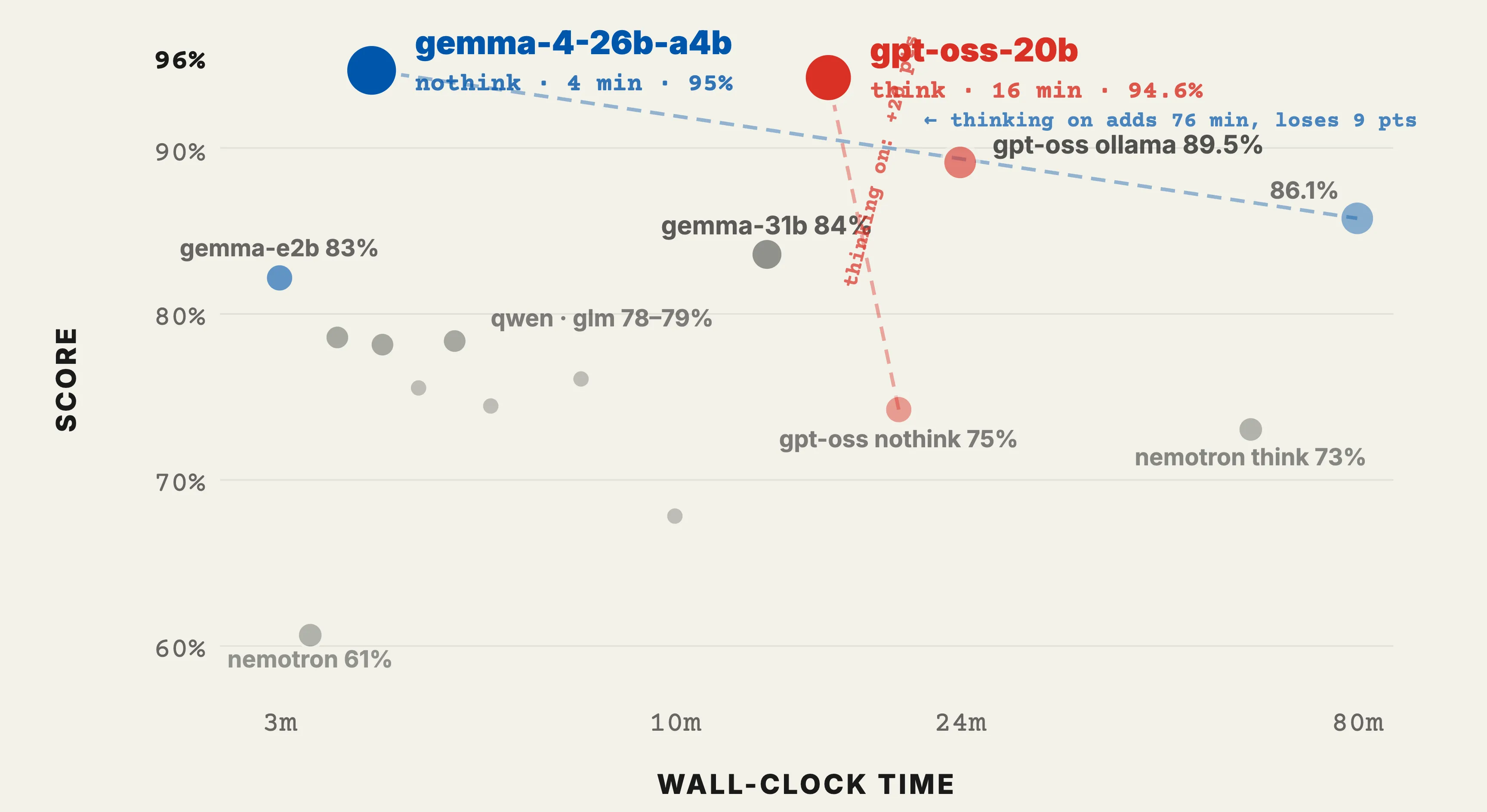
We tested 7 model families across 3 local runtimes on a 64 GB Mac — 20 cells, 5 dimensions. gemma-4-26b-a4b hits 95% in 4 minutes. Thinking mode usually hurts except for tool-calling. Interactive charts and full methodology.
Read the Report →




