







Qodo’s Itamar Friedman presented data: 76% of developers don’t fully trust AI-generated code. “They don’t trust the context that the LLM has.” This isn’t about model capabilities—it’s about whether the harness can maintain enough relevant context while filtering out noise.
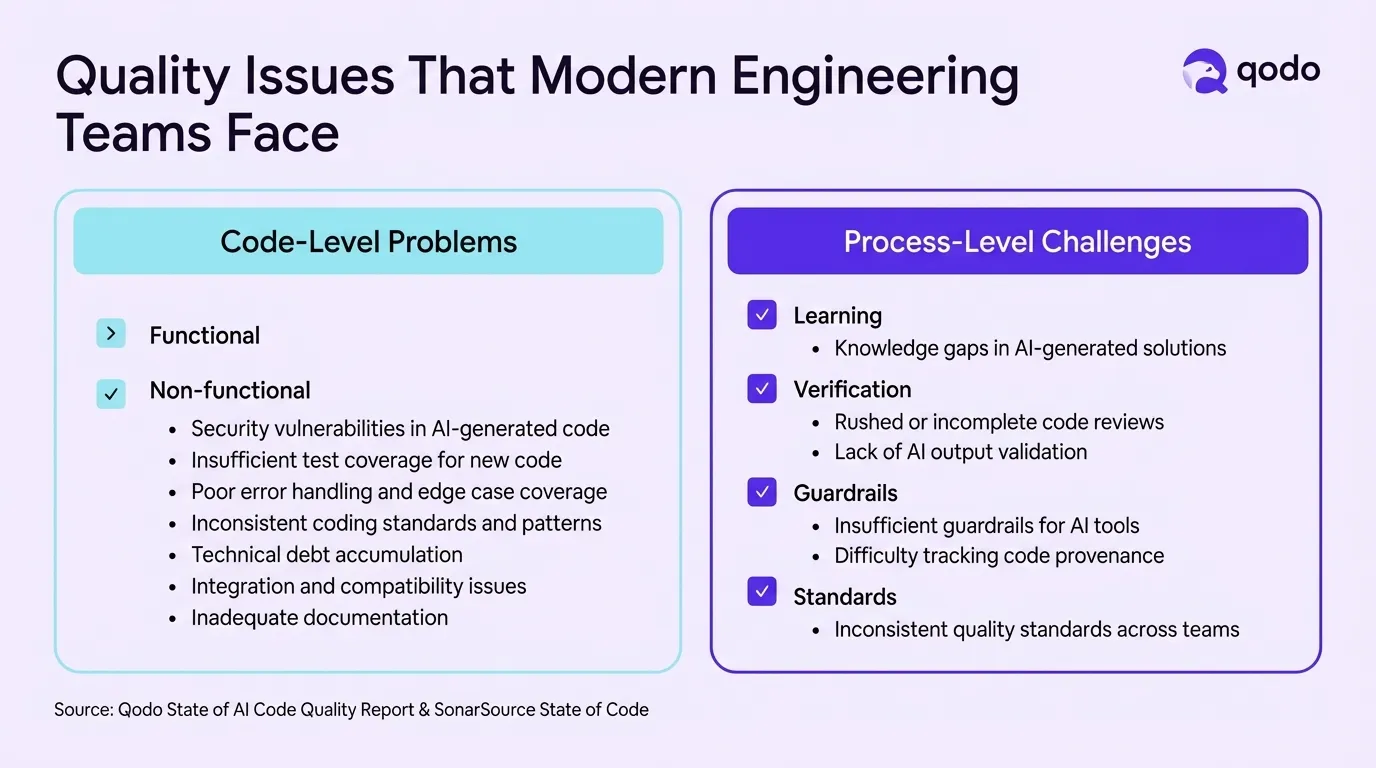
Qodo’s Context Engine pulls in logs, history, and PR comments to give models the right information at the right time. The quality issues teams face split into code-level problems (security vulnerabilities, insufficient test coverage, technical debt) and process-level challenges (learning gaps, inadequate verification, missing guardrails).
Katelyn Lesse, Head of API Engineering at Anthropic, is emphatic: “Memory + Context Editing” is “the way to go” for managing Claude’s working memory. Memory retrieves relevant context when needed. Context Editing clears out the cruft—old tool results, unnecessary content—from the context window.
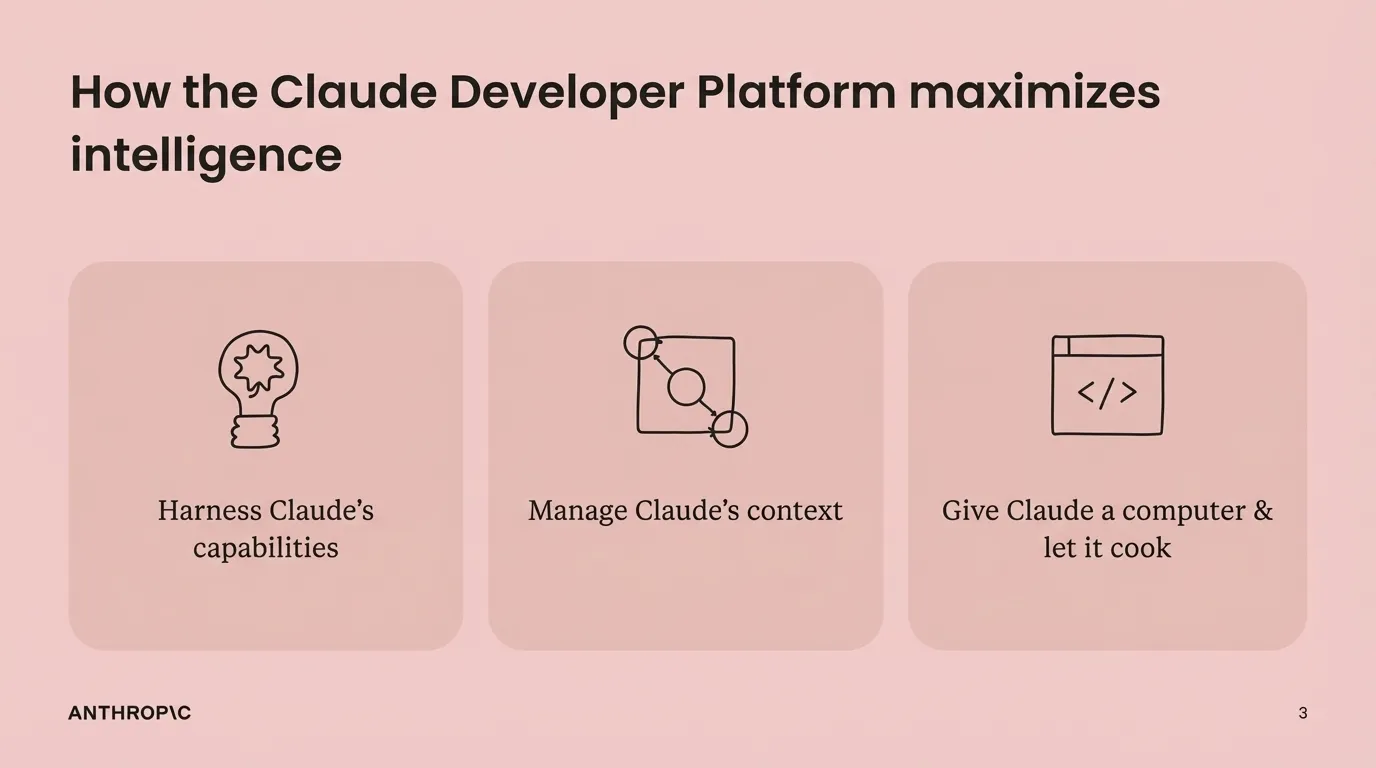
“Effective agentic systems require both expanding capabilities and managing constraints.” Give Claude more tools via MCP and code execution—but also actively manage what stays in memory and what gets pruned. Add features and architect the interaction layer.
“For some, the harness might be the special sauce of the product,” said OpenAI’s Bill Chen. Codex processes dozens of trillions of tokens per week. The harness is where steerability meets reliability, where intelligence combines with habit to keep agents useful across model versions.

“Hard to track the models and we aren’t making the problem easier for anybody.” Don’t bet on any single model. “The harness”—the abstraction layer between models and production: prompts, agent loops, tools, context management. OpenAI claims prompts don’t port well across models, custom tools are out of training distribution, and latency forces context tradeoffs. The harness can help manage the chaos better than prompt microtuning ever could. As Chen put it: “Steerability = intelligence + habit.”
Replit’s VP of AI Michele Catasta has a fix for context pollution: subagents. “Subagent invoked by the core loop with a task and fresh context.” Each subagent gets a clean slate, preventing the gradual degradation when irrelevant info piles up in the context window.

The Browser Company’s Samir Mody treats prompting as craft practiced by many team members beyond engineering. They build prompt editing tools right into internal dev builds. This 10x’d iteration speed. Single-page prompts become multipage skill-generation systems.
The harness is where the game is won or lost. Models keep improving—“new models will raise the trust ceiling”—but the real work is that layer between raw capabilities and production reliability. Parallel tool execution, security sandboxing, context compaction, MCP support. Chen’s advice: “Build where the models are going.” The special sauce isn’t in your model choice—it’s in the abstraction layer you build around it.