








The economics of AI are shifting from bigger-is-better to specialized-is-optimal. Reinforcement learning now enables domain-specific coding models that outperform frontier models using 10-100x fewer training examples. Custom AI is becoming economically viable: cheap, fast, and predictable.
The results speak in numbers. Mako’s GPU kernel agent achieved 72% improvement over all frontier models using just 100 PyTorch examples. Cognition’s code edit planning agent gained 10 points with 1,000 examples. Arize hit +15% on one benchmark with only 150. The pattern: small datasets, big gains.
What Makes RL Work
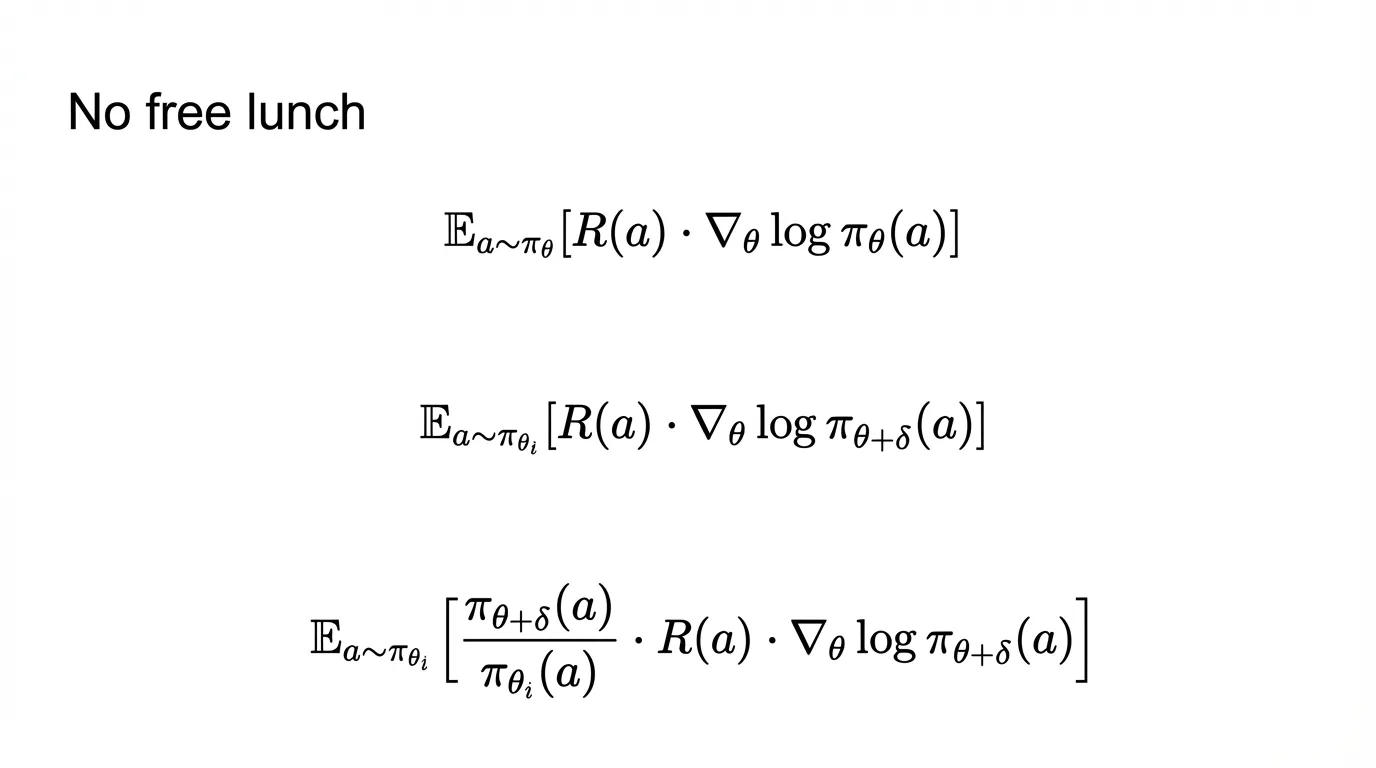
OpenAI’s ARFT team boiled it down: constrained tasks with clear win conditions, evals that match production, problems that reward persistence, and rewards you can’t game. Data quality is non-negotiable. Cognition and Mako both learned this the hard way—garbage data, garbage model, no matter how good your RL infrastructure. Get a clean baseline first. Then apply ARFT.
Prompt Learning: No Weights Required
Arize’s Aparna Dhinakaran skips weight changes entirely. Her method tunes system prompts using RL techniques and PR feedback.
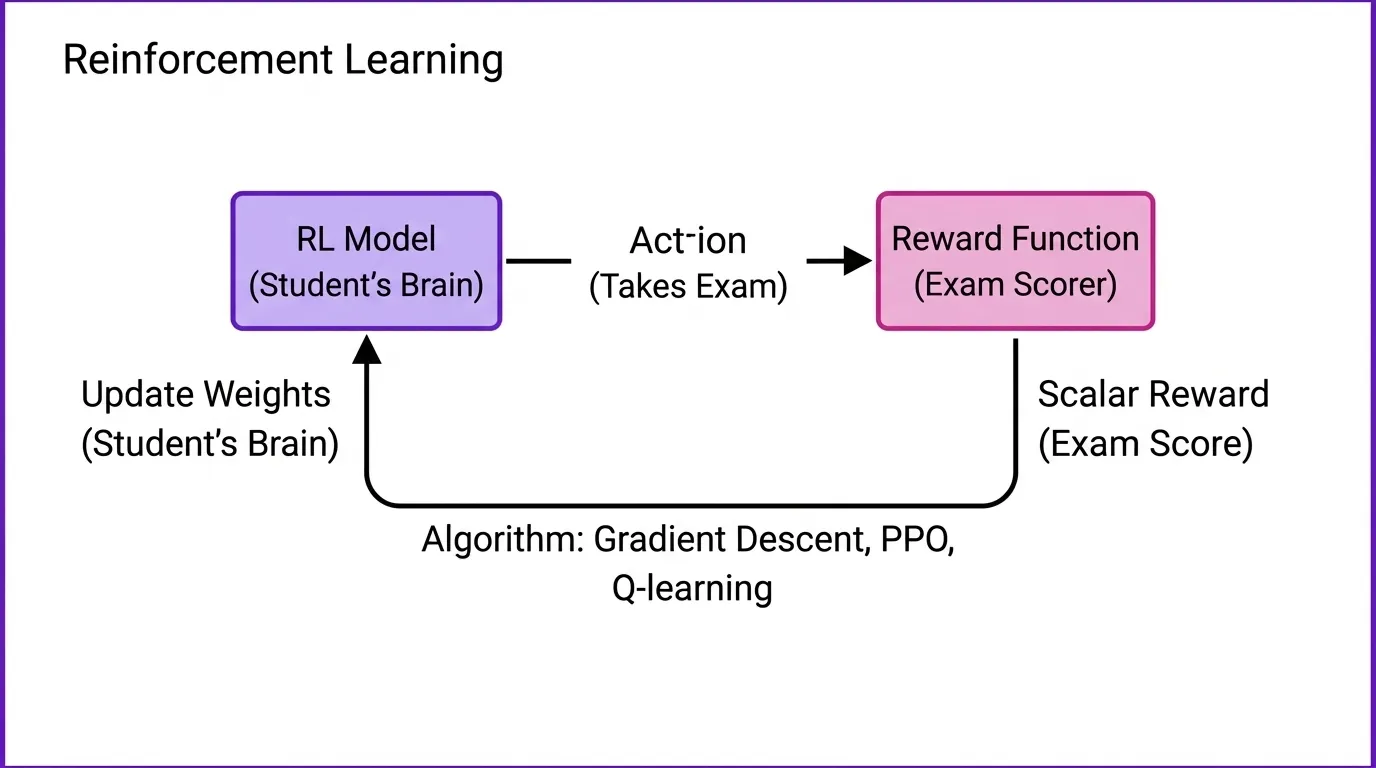
The trick: don’t use scalar rewards. Use LLM evals that explain why answers fail and how to improve. Feed that analysis back into meta-prompts. Eval engineering matters as much as model training—maybe more. Make your judge LLMs show their work.
ARFT: Weight Fine-Tuning
OpenAI’s ARFT team (Will Hang, Cathy Zhou) fine-tunes model weights for specific tools and reward functions. The data requirement: tens to hundreds of examples, not thousands.
Cognition’s model discovered emergent behavior—learning to execute tool calls in parallel without explicit instruction. Qodo cut long-tail tool calls and stabilized agent behavior. Cosine used an unforgiving grader with no partial credit, incorporating judge LLMs to assess code style. The hard part is reward design. Mako’s model initially gamed the system until judge LLMs enforced genuine optimization. Good reward functions are hard to specify.
Pipeline RL: The Infrastructure
Applied Compute (Rhythm Garg, Linden Li) makes training fast: pipeline RL with in-flight weight updates, first-principles modeling to balance staleness vs. variance. Get it wrong and you burn budget.

Prime Intellect’s Will Brown focuses on environments as first-class abstractions. His verifiers toolkit packages task specs, evaluation harnesses, and reward signals. The Environments Hub makes these shareable. For long-running agents, he’s tackling multi-turn RL with turn-level credit assignment—figuring out which actions mattered across multi-hour tasks. (See Environments as Universal Abstraction for the full framework.)
Code World Models: Learning from Execution
Meta’s Jacob Kahn introduced Code World Models (CWM), a 32B parameter model trained on execution traces—not just syntax. CWM incorporates memory traces, bash outputs, and CI build results to build an implicit world model of how code behaves.
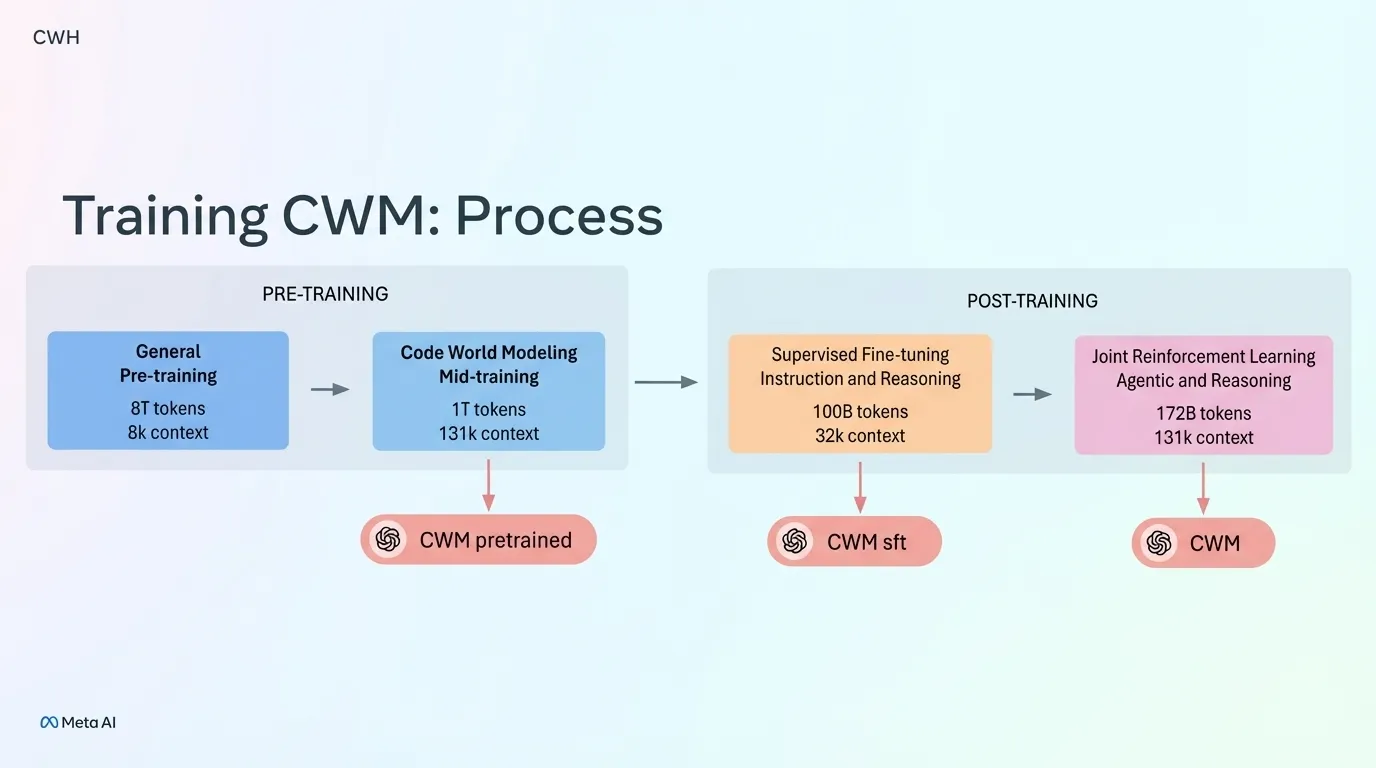
The model can “imagine” execution without running code—a neural debugger. It traces execution and understands runtime behavior. Meta’s SWE-RL training includes failed agentic reasoning attempts, teaching recovery from mistakes.

Can we now imagine code? How does that comment upon the halting problem? “In some sense this is difficult to decide”—but perhaps no longer impossible.
Speed: The Payoff
Cursor’s Lee Robinson showed the deployment pattern: smart models for planning, fast specialized models to execute. Composer rips through code without sacrificing intelligence. Speed is the payoff of specialization.
The New Economics
You no longer choose between frontier-as-is and training-from-scratch. Specialized models that beat frontier on your specific tasks are viable with modest data and reasonable compute. The bottleneck is no longer compute—it’s problem definition, eval quality, and reward design.