Google shipped Gemma 4 in early April 2026: dense e2b / e4b-class models, a 26B MoE (4B active), and a 31B dense variant, Apache 2.0, multimodal context up to 256K on the larger weights. The practical question for builders is not the press release—it’s how those checkpoints behave on the same tasks you already run against GPT, Claude, Gemini, and the open-weights crowd.
We added all four Gemma 4 sizes to our Model Showdown suite in Umwelten and ran them locally via Ollama alongside the existing lineup (OpenRouter, Google direct, DeepInfra, and other Ollama models). Same tracks as the full pipeline (including MCP):
- Reasoning — four classic puzzles, answers scored by a consistent LLM judge (Claude Haiku 4.5).
- Knowledge — thirty short-answer questions across science, geography, history, tech, and a few “tricky” items, judged for factual correctness.
- Instruction — six tasks that punish sloppy formatting (JSON, markdown tables, constrained prose).
- Coding — small deterministic challenges in multiple languages; code is extracted, compiled or interpreted, and checked against fixtures.
- MCP tool use — one multi-step prompt against the TezLab MCP server (real vehicle, battery, charging, and charger data). Scoring is a deterministic tool checklist (six expected capabilities, e.g. listing vehicles, battery health, charges, efficiency, “my chargers,” and finding nearby public chargers) plus the same style of LLM judge we use elsewhere (quality of synthesis and recommendations).
Below is what stood out when we compared Gemma 4 to frontier APIs and to open / budget hosted models—not a replacement for Google’s own benchmarks, but a cross-model slice using our harness and our mix of tasks.
TL;DR
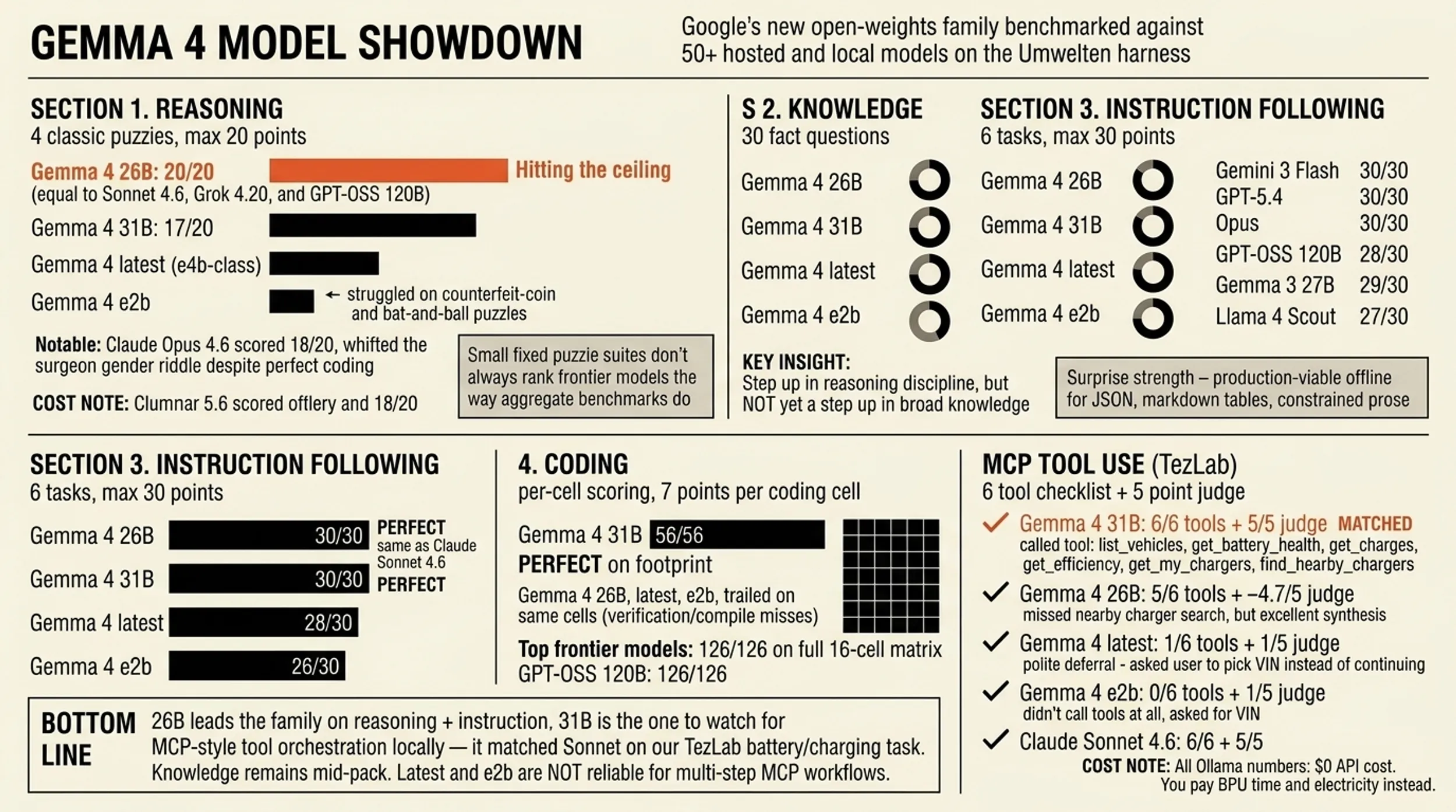
| Lens | Gemma 4 (local, Ollama) | Frontier (API) | Open / value (hosted) |
|---|---|---|---|
| Reasoning (4 puzzles) | 26B hit the reasoning ceiling (20/20) in our battery—same top band as Sonnet 4.6, GPT‑OSS 120B, Grok 4.20, etc. 31B scored 17/20; e2b struggled on the hardest puzzle (counterfeit-coin style logic). | Sonnet 4.6 100% combined across all four showdown dimensions; Gemini 3 Flash and GPT‑5.4 sat around ~99% combined. Opus 4.6 still missed one reasoning puzzle (18/20) despite perfect coding—showing these small suites can expose surprising weak spots. | GPT‑OSS 120B (~98% combined) remains the open-weights hosted reference on this suite; DeepSeek V3.2, Llama 4 Scout/Maverick, and Gemma 3 27B sit in the high 80s–low 90s combined. |
| Knowledge (30 questions) | All Gemma 4 variants clustered around 18–22 / 30 correct—clearly behind frontier models at 29–30/30 and behind GPT‑OSS 120B (28/30). Roughly in the band of Llama 4 Scout (27/30) on this quiz set. | Strongest models rarely miss more than one or two items. | Larger open / mid-price models still beat Gemma 4 on raw fact recall here. |
| Instruction (6 tasks) | 26B and 31B: 30/30—full marks, same ceiling as Sonnet on this track. Default / e4b-class (latest): 28/30. e2b: 26/30. | Top APIs almost all at or near the ceiling. | Competitive with strong instruction-tuned open models. |
| Coding | The suite combine now uses a per-task denominator (7 points per coding cell), so partial runs show points earned / points possible for the tasks on disk—e.g. 56/56 when eight cells exist—not a bogus 28/126. In our April run, 31B cleared 56/56 on that footprint; 26B, latest, and e2b trailed on the same cells (verification or compile misses). 126/126 still means a full 18-cell matrix; use coding-eval.ts --all --new when you want every challenge×language for cross-model breadth. | Full 126/126 on the complete coding suite for the top finishers. | GPT‑OSS 120B 126/126; smaller open models vary by task. |
| MCP (TezLab) | 31B: full 6/6 tool checklist + 5/5 judge—same bar as Claude Sonnet 4.6 on this prompt (both hit every required tool class including find/search chargers, strong narrative). 26B: 5/6 tools (everything except the nearby/alternative charger search) but still ~4.7/5 judge—excellent synthesis with real kWh, locations, and degradation numbers. latest: only list_vehicles, then asked the user to pick a VIN instead of continuing—1/6 tools, judge 1/5. e2b: no tools—asked for a VIN without calling list_vehicles—0/6, judge 1/5. | Sonnet 6/6 + 5/5 on this run; Opus and other top models also cluster at the top of the MCP leaderboard. | GPT‑OSS 120B often misses one or two checklist items (e.g. efficiency / my chargers) but can still earn a 5/5 judge on prose—tool discipline and narrative don’t always move together. Gemma 3 27B (OpenRouter) did not execute tools in our run due to a provider routing / tool-use error, so it isn’t comparable to Gemma 4 31B on Ollama for MCP. |
Bottom line: Gemma 4 26B still leads the family on reasoning + instruction; 31B is the one to watch if you care about MCP-style tool orchestration locally—it matched Sonnet on our TezLab battery/charging task. Knowledge remains mid-pack versus hosted open weights; coding scores in combined reports are now honest for whichever cells ran—run a full coding pass when you need the full 126-point spread; latest and e2b are not reliable for multi-step MCP workflows without more prompting or tooling.
Reasoning: local 26B next to Sonnet—and ahead of Opus on this quiz
Reasoning scores are the sum of four judge grades (5 points each, max 20). Gemma 4 26B achieved 20/20, in the same cluster as Claude Sonnet 4.6, xAI Grok 4.20, OpenAI GPT‑OSS 120B, and several others.
Claude Opus 4.6—despite perfect marks on knowledge and coding in this run—landed 18/20 on reasoning because it whiffed the surgeon gender riddle (3/5 on that puzzle). That’s a useful reminder: small, fixed puzzle suites don’t always rank “frontier” models the way aggregate benchmarks do.
Gemma 4 31B scored 17/20; e2b and latest were lower, with the bat-and-ball and counterfeit coin puzzles doing the most damage—exactly the classic System‑1 traps you’d expect smaller or less aligned checkpoints to stumble on.
Knowledge: where hosted open weights still win
On 30 fact questions, Gemma 4 variants scored 22/30 (26B, 31B, latest) or 18/30 (e2b). For comparison on the same questions:
- Gemini 3 Flash, GPT‑5.4, Opus: 30/30 (or 29/30 where noted in the full table).
- GPT‑OSS 120B: 28/30.
- Gemma 3 27B (OpenRouter): 29/30.
- Llama 4 Scout: 27/30.
So Gemma 4 is a step up in reasoning discipline for a local model, but not yet a step up in broad knowledge versus the best open-weights hosted checkpoints on this quiz.
Instruction following: the surprise strength
Gemma 4 26B and 31B both scored 30/30 on the six instruction tasks—perfect alignment with Claude Sonnet 4.6 on that axis. If you’re building agents that must emit valid JSON, markdown tables, and tightly scoped prose, the larger Gemma 4 checkpoints look production-viable offline, at least on this stress test.
Coding: per-cell scoring in the combine, full grid when you need it
We fixed the suite loader in Umwelten so multi-task dimensions (coding, reasoning, knowledge, instruction, MCP) add the right denominator per result file instead of always dividing by the full-run maximum. On the combined leaderboard, coding now reads like 56/56 or 119/126—never 28/126 when only eight cells were evaluated.
On the footprint we had in April 2026, Gemma 4 31B went 56/56; the other Gemma 4 sizes showed gaps on the same cells (including a Go compile failure on e2b in an earlier slice). Sonnet-class models still anchor the 126/126 end when the entire 6×3 challenge grid is present.
MCP (TezLab): 31B matches Sonnet; 26B almost nails it; small / default tiers stall
The MCP prompt asks for battery health, charging patterns, efficiency, your usual chargers, and better public alternatives nearby—the sort of thing a product assistant would do over TezLab’s MCP server (same stack we described in the Mercury / MCP tool eval post).
On the April 2026 run artifacts:
-
Gemma 4 31B (Ollama) called
list_vehicles,get_battery_health,get_charges,get_efficiency,get_my_chargers, andfind_nearby_chargerswith sensible coordinates—6/6 on the rubric—and the judge scored it 5/5 for synthesis, grounding, and actionable advice (specific % degradation, kWh, cycle counts, home vs DC patterns, and honest “no 50 kW+ public options within 15 km” style conclusions when the tools return that). That’s the same tool + judge ceiling as Claude Sonnet 4.6 on this task. -
Gemma 4 26B did strong multi-vehicle work (both VINs for battery, charges, efficiency, my chargers) but never invoked the nearby / search charger tool—5/6 tools. The judge still rated it ~4.7/5: the write-up was detailed and grounded, but the rubric treats missing the charger-discovery step as a real gap for a user who explicitly asked for alternatives.
-
gemma4:latest(e4b-tier default) listed both vehicles correctly then stopped and asked the user which VIN to analyze—1/6 tools, 1/5 judge: the failure mode is “polite deferral” instead of driving the toolchain to completion. -
gemma4:e2bdid not call tools at all and asked the user for a VIN—0/6 tools, 1/5 judge. That’s the harshest split in the family: the smallest checkpoint didn’t latch ontolist_vehicleseven though the tools were available.
For open-weights hosted contrast on the same harness: GPT‑OSS 120B can skip checklist items (e.g. efficiency / my chargers) while still getting a 5/5 narrative judge—useful prose, incomplete tool coverage. Gemma 3 27B on OpenRouter never reached the tools in our run (provider error: no tool-capable endpoint with our routing), so treat that row as infra, not capability; Gemma 4 31B on Ollama is the meaningful Gemma-line MCP data point here.
run-all in Umwelten now always runs this MCP suite after the four core evals (TezLab OAuth must be set up once; we also keep a small examples/mcp-chat/test-connection.ts smoke test).
Cost and latency narrative
All Ollama numbers above are $0 API cost; you pay GPU time and electricity instead. Wall-clock on local hardware varies widely; in our run, Gemma 4 e2b was the fastest local Gemma on several steps, while 26B/31B traded time for quality—still orders of magnitude cheaper than multi-dollar frontier rollups if you batch offline.
How to reproduce
- Install weights from Ollama’s Gemma 4 library (
gemma4:e2b,gemma4:latest,gemma4:26b,gemma4:31b). - Clone Umwelten, configure provider keys for the hosted models you want in the lineup.
- Run the showdown (example):
dotenvx run -- pnpm exec tsx examples/model-showdown/run-all.ts --all
That includes MCP after reasoning, knowledge, instruction, and coding. Use--newwhen you want a fresh run directory; omit it to resume and reuse caches. - Optional:
dotenvx run -- pnpm exec tsx examples/mcp-chat/test-connection.tsto verify TezLab MCP before a long run.
Reasoning, knowledge, instruction, and coding numbers are from the April 2026 Model Showdown (reasoning run 007, knowledge/instruction runs 002, coding run 006). MCP findings are from the same campaign’s TezLab eval artifacts (model-showdown-mcp run 001, per-model results/*.json): we quote tool checklist + judge explicitly for Gemma 4 and a few reference models. If you publish this post, swap the hero image / ogImage in frontmatter for a Gemma-specific graphic when you have one.
Will Schenk April 4, 2026