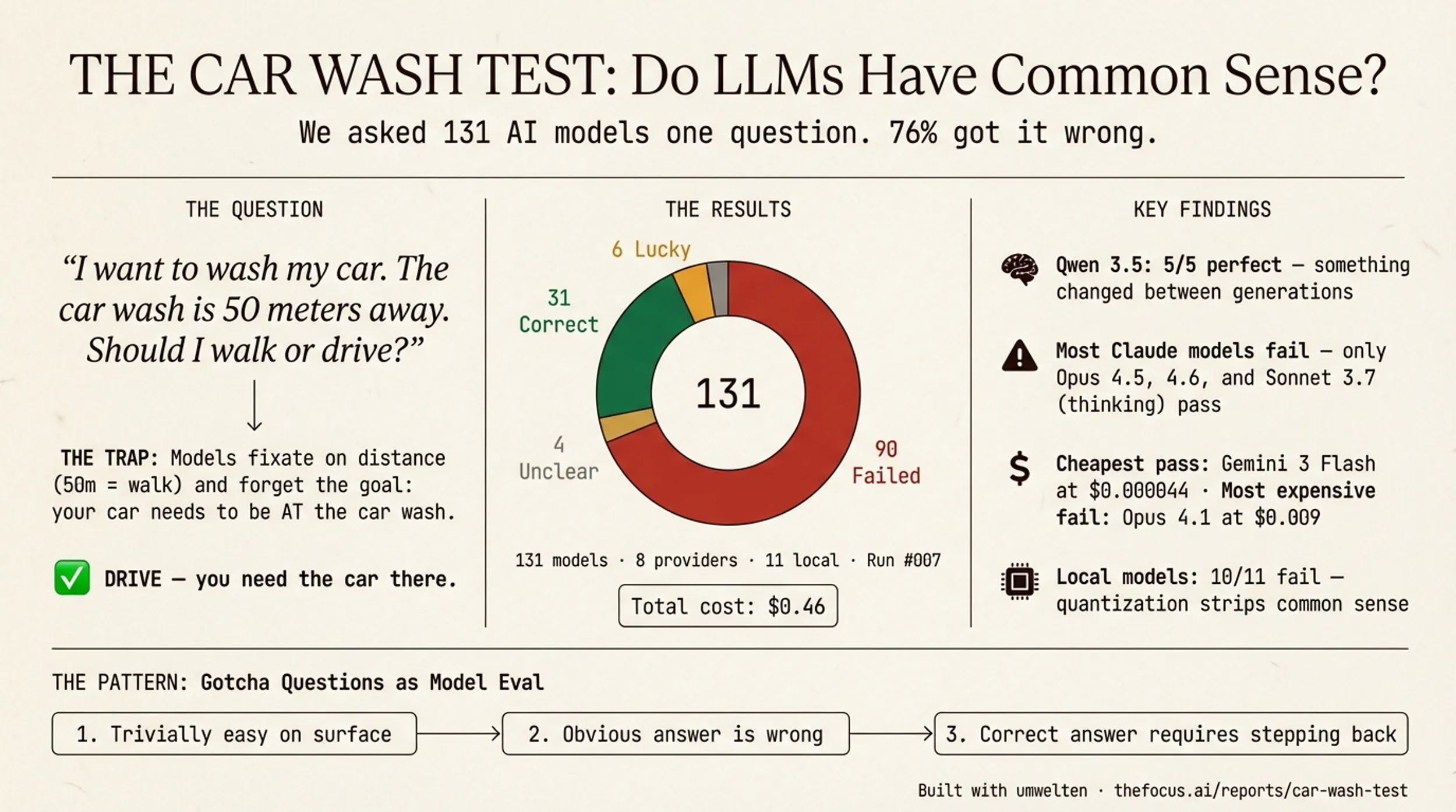
The question is:
“I want to wash my car. The car wash is 50 meters away. Should I walk or drive?”
Is it common sense? Is it a trick question? Will the models get it right? Betteridge’s law of headlines is an adage that states: “Any headline that ends in a question mark can be answered by the word no.” — and 76% of AI models get this wrong. They will consider a whole host of other ideas — environmental impact, the value of exercise, fuel economy — ignoring the fact that you need your car at the car wash to wash it.
We replicated Opper.ai’s Car Wash Test across 131 models, 8 providers, and 11 local Ollama models. The full interactive report has charts, sortable tables, and per-model reasoning. Here’s what stood out.
The results
- 31 correct — said “drive,” understood the car must be present
- 6 lucky — said “drive” for wrong reasons (convenience, speed)
- 90 failed — said “walk” with confident, elaborate, wrong reasoning
- 4 unclear/error
Qwen 3.5 went 5 for 5. Every model passed. Their Qwen 3 siblings all fail — something fundamental changed between generations.
Most Claude models fail. Only Opus 4.5, Opus 4.6, and 3.7 Sonnet (thinking mode) pass. Sonnet 4.6 — the model I use daily — fails.
Cost doesn’t buy common sense. Gemini 3 Flash passes at $0.000044. Claude Opus 4.1 fails at $0.009.
Local models are a wipeout. 10 of 11 Ollama models failed, suggesting quantization strips common-sense reasoning.
Explore the Full Interactive Report →
Why testing matters
We’ve built umwelten, a comprehensive toolkit for monitoring agents, building agents, and, in this use case, evaluating models and their responses. Figuring out cost vs speed vs intelligence metrics. We are still early in the game and vibing feels are still the real way that we see how things work. (A single prompt in a controlled setting isn’t really enough to compare Kimi K2.5 vs Opus 4.6, but real usage makes it clear.)
I love these questions. I still don’t really understand “Why is it dark at night?” and in AI for research, “Why is it dark at night?” separates models that give the obvious answer from those that reach Olbers’ Paradox — and I really want them to point me to Poe’s Eureka poem. “Who is the monster in Frankenstein?” — covered in Moral Vibe Check — also gets to the moral understanding of these models. Generally most models said the monster in Frankenstein is the creature — technically correct but missing the deeper point of the story.
The pattern: they so easily blather on and on in an intelligent-seeming way, but it’s so superficial. When they reach our own, personal level of superficial I hope the models keep going, but now it’s trivially easy to get them on gotcha-type questions.
So how can we get a sense of what we are dealing with?
Build your own
The Car Wash Test cost $0.46 across all 131 models. It tells me more about real-world reasoning than any aggregate benchmark.
We built this with umwelten, our eval framework — define a prompt, run it against models, have a judge score results. Your eval should test what matters to you: weird customer edge cases, domain-specific reasoning, whatever your model actually needs to handle.
Every team using LLMs in production should have a handful of gotcha questions for their domain. Not as a replacement for systematic eval — but as a fast, cheap litmus test. If your model can’t see past the obvious, it shouldn’t be making decisions on your behalf.
All of the emdashes in the post were typed by a human.
Will Schenk March 1, 2026
