What We Tested
7 model families across 3 runtimes, producing 20 (model, runtime, thinking-mode) cells. All models run on a single 64 GB Apple Silicon machine.
The Models
The Runtimes
| Runtime | Engine | Thinking | Notes |
|---|---|---|---|
| Ollama | ollama daemon | Default (model decides) | Q4_K_M for all; Go-template chat approximations |
| llamaswap | llama-server + llama-swap | On (default) | --ctx-size 0 --jinja — native chat template |
| llamaswap-nothink | llama-server + llama-swap | Off (enable_thinking=false) | Same binary, thinking suppressed per-request |
The 5 Evaluation Dimensions
| Dimension | Scoring | Max | Method |
|---|---|---|---|
| Instruction Following | Deterministic constraint checking | /30 | 6 tasks, 5 pts each |
| Reasoning | LLM judge (Claude Haiku 4.5) | /20 | 4 puzzles, 5 pts each |
| Coding (Write) | Compile + run + verify output | /126 | 6 problems × 3 languages × 7 pts |
| Coding (Fix) | Hidden test harness | /25 | 5 buggy JS functions, 5 pts each |
| Tool Math | Correctness + tool-call counting | /25 | 5 multi-step arithmetic tasks |
The Surprising Conclusions
- The runtime barely matters. Ollama and llamaswap score within a few points of each other on every model when you control for quantization and thinking mode.
- Thinking mode usually hurts on short-horizon tasks — except for tool-calling, where it’s required.
- gpt-oss-20b on llamaswap (thinking on) is the best small open model for tool-calling. 23/25.
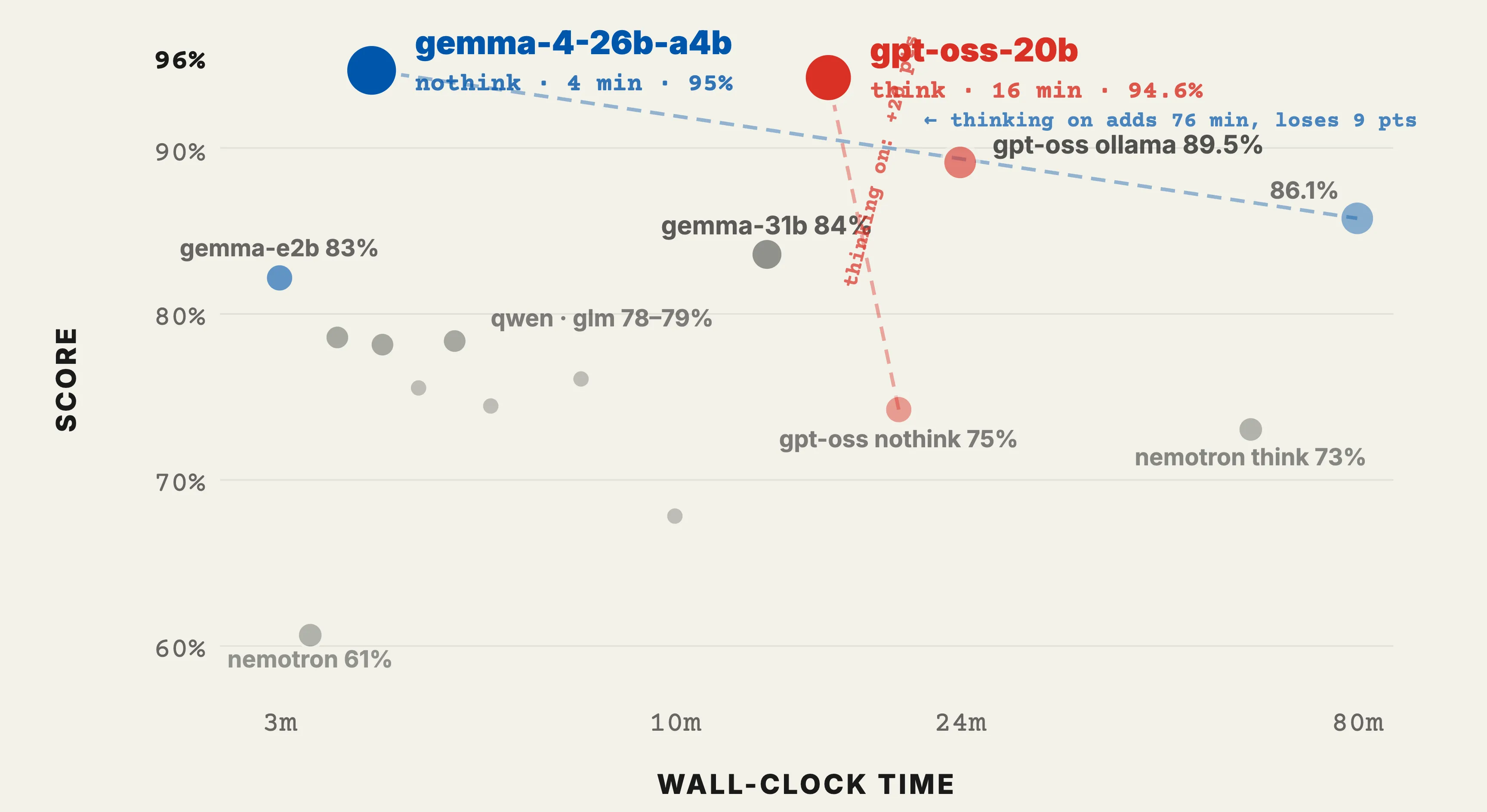
- gemma-4-26b-a4b is the best value model overall. 95.0% combined in 4 minutes.
- Tool-calling is where the matrix falls apart. Three cells scored 0/25, eight scored ≤5/25.
- A 4B model cannot fix its own broken code from the compile error. 0 improvements across 8 retries.
- Thinking mode can turn 4-minute runs into 1.5-hour runs. Pure cost, negative benefit on short tasks.
- gemma-4-31b is paradoxically worse than gemma-4-26b-a4b. The MoE model with 4B active params outperforms the larger dense variant on tool-calling.
- The ollama vs llamaswap question is decided by configurability, not performance.
Overall Results
How “Best” Was Decided
| Model | Instruction | Reasoning | Code (Write) | Code (Fix) | Tool Math | Combined % | Time |
|---|---|---|---|---|---|---|---|
| gemma-4-26b-a4b (llamaswap-nothink) | 30/30 | 20/20 | 120/126 | 25/25 | 20/25 | 95.0% | 4m13s |
| gpt-oss-20b (llamaswap) | 30/30 | 17/20 | 121/126 | 25/25 | 23/25 | 94.6% | 16m6s |
The “Combined %” is the mean of the per-dimension percentages, not a weighted score. Both models tie on Instruction (100%) and Coding-fix (100%). Gemma wins reasoning by 3 points; gpt-oss wins tool-math by 3 points and coding-write by 1. They cancel out within 0.4%.
“Best raw scores on tool-calling” → gpt-oss-20b llamaswap (23/25)
“Best general-purpose at reasonable cost” → gemma-4-26b-a4b llamaswap-nothink
“Best out-of-the-box” → gemma4:31b ollama (84.0%, no thinking-mode tuning required)
Methodology
Run Mechanics
The matrix runner iterates model-major: load one model, run all five evaluation suites, evict before loading the next. Required on a 64 GB machine because most models are 17–19 GB resident. 20-min per-cell watchdog, 5-min per-task watchdog. Partial responses are scored as-is.
All quantizations are Q4_K_M across runtimes (apples-to-apples), except gpt-oss which ships natively as MXFP4. Total matrix wall-clock time: 316 minutes (~5.3 hours).
Instruction Following DETERMINISTIC · /30
Can the model follow precise format instructions without overshooting? No reasoning needed; just literal compliance.
The Exact Prompts
1.1 Exact Word Count (5 pts)
Write a sentence about the ocean that contains EXACTLY 12 words. Do not include any other text, explanation, or commentary.
Scoring: 5 if exactly 12 words; 3 if off by 1; 1 if off by 2–3; 0 otherwise.
1.2 Structured JSON Output (5 pts) — 4 typed fields, no markdown fences.
1.3 Constrained List (5 pts) — 5 animals, numbered, alphabetical, ≤8 chars.
1.4 Negative Constraints (5 pts) — sunset description avoiding 3 words.
1.5 Format Transformation (5 pts) — CSV to markdown table.
1.6 Multi-format Response (5 pts) — 3 sections separated by ---.
What We Saw
Eleven of 20 cells scored a perfect 30/30. The most discriminating task was exact-word-count:
- Thinking mode hurt word counting. gemma-4-26b-a4b llamaswap (thinking on) scored 0/5. Same weights, thinking off: 5/5.
- glm-4.7-flash scored 1/5 — writes nicely but cannot constrain length.
Reasoning LLM JUDGE · /20
Classic reasoning puzzles where the obvious answer is wrong. Claude Haiku 4.5 as judge.
2.1 The Surgeon Riddle · 2.2 Bat and Ball · 2.3 Lily Pad · 2.4 Counterfeit Coin
Twelve cells scored 17–20/20. gemma-4-31b scored 20/20 on both runtimes. The hardest puzzle was counterfeit-coin.
Signal: On short reasoning puzzles, model size matters more than thinking-mode budget.
Coding — Write COMPILE + RUN + CHECK · /126
6 problems × 3 languages (TypeScript, Python, Go), each scored 0–7. Top scorers: gemma-4-31b (126/126 on both runtimes).
The dominant failure mode in Go: Of 35 non-perfect Go scores, 67% were compile errors — “imported and not used” or “declared and not used.”
Coding — Fix HIDDEN TEST HARNESS · /25
5 buggy JavaScript functions. Sixteen of 20 cells scored a perfect 25/25. The four that lost points: all three nemotron variants and gemma4-e2b ollama. This dimension has the least signal — too easy for most models.
Tool Math CORRECTNESS + TOOL-CALL COUNTING · /25
Can the model use provided tools (calculator, statistics) to chain multi-step arithmetic?
| Model | Tool Math |
|---|---|
| gpt-oss-20b llamaswap (thinking-on) | 23/25 |
| gemma-4-26b-a4b llamaswap (thinking-on) | 20/25 |
| gemma-4-26b-a4b llamaswap-nothink | 20/25 |
| gpt-oss-latest ollama | 20/25 |
| gemma-4-31b llamaswap (thinking-on) | 20/25 |
| glm-4.7-flash-latest ollama | 14/25 |
| gemma-4-e2b llamaswap-nothink | 12/25 |
| … | … |
| gemma4-26b ollama | 0/25 |
| gpt-oss-20b llamaswap-nothink | 0/25 |
Why Tool-Calling Is So Weak
- Models try to one-shot the answer instead of chaining tools.
- Thinking-off models get stuck. gpt-oss-20b nothink: 0/25. Same model thinking-on: 23/25.
- Tool-calling format errors. Wrong argument shapes exhaust the retry budget.
- Long chains exceed the watchdog.
- Reasoning loops on Stats+arithmetic. Models re-derive instead of trusting tool output.
Root cause: Tool-calling requires the model to maintain state across multiple turns and trust intermediate results. Smaller and thinking-off models fail this.
Coding 2-Pass — The Experiment /126
If a model fails in round 1, does showing it the actual compile/runtime error help?
| Round 1 | Round 2 | Δ | |
|---|---|---|---|
| Variant A (scaffolded) | 93/126 (73.8%) | 79/126 (62.7%) | −14 pts |
| Variant B (raw error) | 93/126 (73.8%) | 80/126 (63.5%) | −13 pts |
Same outcome. Zero improvements. The 4B model correctly identified the fix for one error and then introduced a new error elsewhere.
The 4B-parameter model genuinely lacks the capacity to make a localized fix without disturbing surrounding code. It’s not context length, not prompt format — it’s model capability.
What This Means in Practice
| Use Case | Pick |
|---|---|
| Best general overall, low cost | gemma-4-26b-a4b on llamaswap-nothink (95.0%, 4 minutes) |
| Best for tool-use / agent loops | gpt-oss-20b on llamaswap (thinking on) (94.6%, 23/25 on tool math) |
| Best out-of-the-box | gemma4:31b on ollama (84.0%, no config needed) |
| Smallest still usable | gemma-4-e2b on llamaswap-nothink (82.6%, 3 minutes) |
| What to avoid | Thinking-on by default for non-agent tasks. The wall-clock cost is huge. |
If you’re iterating on agent loops that need the model to use compile/test feedback to fix its own code: don’t trust models below ~20B parameters to do this reliably.