Everyone says local models are getting good. We wanted numbers.
We ran 7 model families across 3 local runtimes on a single 64 GB Apple Silicon machine — 20 combinations total, scored across 5 dimensions: instruction following, reasoning, code generation, bug fixing, and tool use. The full report has the interactive charts and complete methodology. Here’s what surprised us.
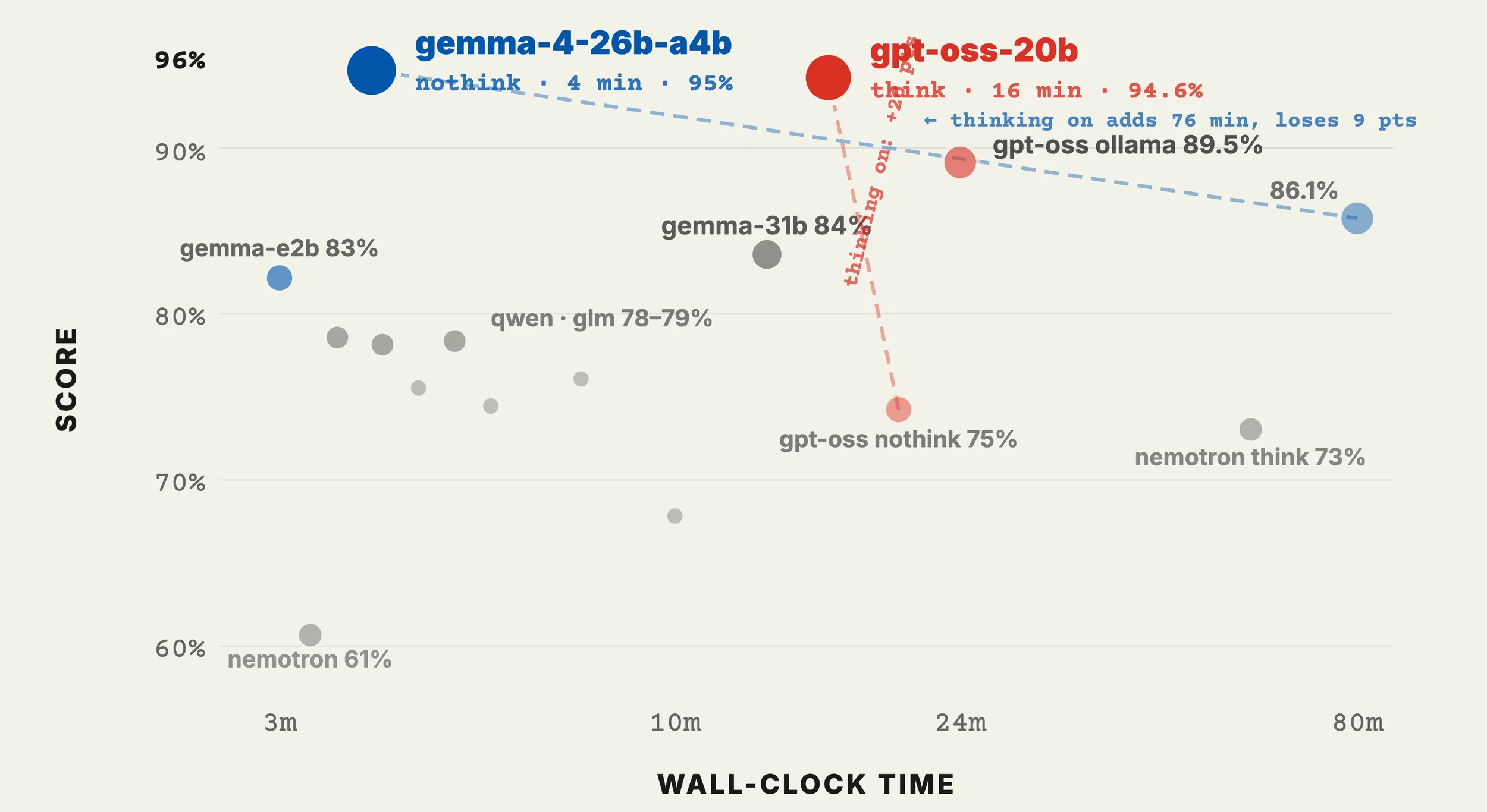
The headline: gemma-4-26b-a4b wins, and it’s not close on efficiency
95% combined score in 4 minutes and 13 seconds. That’s with thinking turned off, running on llamaswap with Q4_K_M quantization. For context, gpt-oss-20b — the runner up — scores 94.6% but takes 16 minutes. Both are excellent, but the gemma model is 4x faster for nearly identical quality.
The small print: gemma’s only weakness is tool-calling (20/25 vs gpt-oss’s 23/25). If your workload is primarily agentic tool use, gpt-oss-20b with thinking on is the pick.
The runtime barely matters
This was the most surprising finding. Ollama and llamaswap score within a few points of each other on every model when you control for quantization and thinking mode. The entire ollama-vs-llamaswap debate is about configurability and deployment ergonomics, not model performance.
If you just want something that works out of the box: ollama run gemma4:31b gets you 84% with zero configuration. If you want to squeeze out that last 10% and control thinking mode per-request, llamaswap with --jinja gives you the knobs.
Thinking mode usually hurts
This was counterintuitive. On short-horizon tasks — instruction following, reasoning puzzles, code generation — turning thinking on makes things worse. gemma-4-26b-a4b with thinking on drops from 95% to 86.1% and takes 80 minutes instead of 4.
The one exception: tool-calling. gpt-oss-20b scores 0/25 with thinking off and 23/25 with thinking on. The model literally cannot chain tool calls without the internal reasoning step. Same weights, same runtime, thinking is the only variable.
The lesson: don’t turn thinking on by default. Use it selectively for agentic workloads that require multi-step tool orchestration.
Tool-calling is where local models fall apart
This is the dimension that separates good from great. Three cells scored 0/25 on tool math. Eight scored 5 or below. The failure modes are revealing:
- Models try to one-shot the answer instead of chaining calculator calls
- Format errors exhaust the retry budget — wrong argument shapes, hallucinated function names
- Models re-derive intermediate results instead of trusting tool output
- Long chains exceed the watchdog timer
If you’re building agent loops that need reliable tool use, you need either a 20B+ model with thinking on, or you need to accept that cloud APIs are still the right choice for this workload.
Small models can’t fix their own code
We ran an experiment: when a 4B model produces code that fails to compile, show it the error and let it try again. Two variants — one with scaffolded hints, one with just the raw error.
Result: zero improvements across 8 retries. The model correctly identified the fix for one error and then introduced a new bug elsewhere. It’s not a prompting problem or a context length problem — the 4B parameter count genuinely can’t hold the full program in working memory while making a localized fix.
If you’re building iterative code-fix loops: don’t trust anything below ~20B parameters for this.
What to actually use
| Use case | Pick |
|---|---|
| Best overall (95%, 4 min) | gemma-4-26b-a4b on llamaswap, thinking off |
| Best for tool-use / agents | gpt-oss-20b on llamaswap, thinking on |
| Best out-of-the-box | gemma4:31b on ollama (no config needed) |
| Smallest still usable | gemma-4-e2b on llamaswap, thinking off (82.6%, 3 min) |
| What to avoid | Thinking-on by default for non-agent tasks |
The full report has per-dimension breakdowns, the complete 20-cell matrix, and the exact prompts we used for each evaluation dimension: Local Providers: Full Assessment.
Will Schenk May 12, 2026